
blog – 2023-10-19 - Training
 Ready to supercharge your Python skills? Embark on a journey into the world of parallel Python with our first episode in this blog series. Read More ›
Ready to supercharge your Python skills? Embark on a journey into the world of parallel Python with our first episode in this blog series. Read More ›
blog – 2023-09-22 - Training
 Places are now available for upcoming Research Computing training courses, sign up now! Read More ›
Places are now available for upcoming Research Computing training courses, sign up now! Read More ›
blog – 2023-06-01 - Training
Places are now available for upcoming Research Computing training courses, sign up now! Read More ›
blog – 2023-04-25 - RSE
 Read about a recent RSE project that looked at building an R package and some tips along the way. Read More ›
Read about a recent RSE project that looked at building an R package and some tips along the way. Read More ›
blog – 2023-04-19 - HPC
Installing geospatial R packages can be challenging on HPC, conda provides on possible solution to this problem. Read More ›
blog – 2023-04-05 - Training
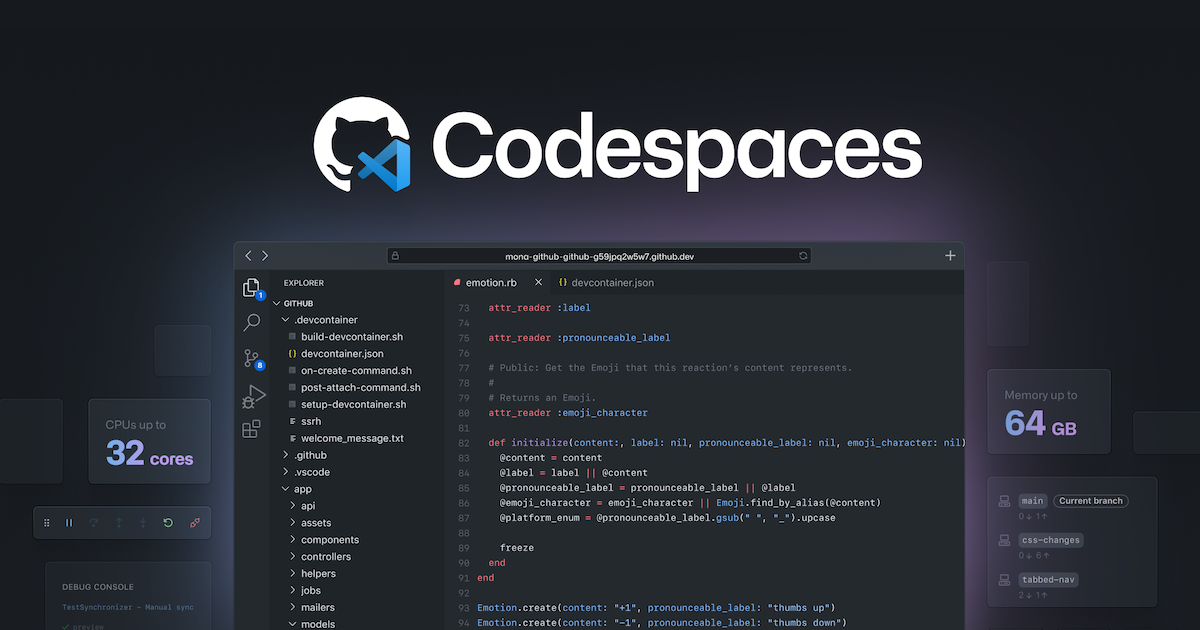 GitHub Codespaces offering an interesting option for easy to spin up computational teaching environments Read More ›
GitHub Codespaces offering an interesting option for easy to spin up computational teaching environments Read More ›
blog – 2023-04-05 - Recruitment
We'll soon be advertising some opportunities to join our team. Read more to find out what we're about! Read More ›
blog – 2023-01-30 - Training
 Places are now available for upcoming Research Computing training courses, sign up now! Read More ›
Places are now available for upcoming Research Computing training courses, sign up now! Read More ›
blog 2023-01-16 -
![]() A roundabout tinker with useful with tools to install research software Read More ›
A roundabout tinker with useful with tools to install research software Read More ›
blog – 2022-12-15 - That's a wrap on 2022!
A final post from the team looking back on 2022. Read More ›
blog – 2022-12-12 - 🎄12 Days of HPC 2022
![]() Blog post number 12 in our 12 days of HPC series from Astrophysics (Physics & Astronomy)! Read More ›
Blog post number 12 in our 12 days of HPC series from Astrophysics (Physics & Astronomy)! Read More ›
blog – 2022-12-11 - 🎄12 Days of HPC 2022
![]() Blog post number 11 in our 12 days of HPC series from School of Computing and Faculty of Biological Sciences! Read More ›
Blog post number 11 in our 12 days of HPC series from School of Computing and Faculty of Biological Sciences! Read More ›
blog – 2022-12-10 - 🎄12 Days of HPC 2022
![]() Blog post number 10 in our 12 days of HPC series from School of Computing! Read More ›
Blog post number 10 in our 12 days of HPC series from School of Computing! Read More ›
blog – 2022-12-09 - 🎄12 Days of HPC 2022
![]() Blog post number 9 in our 12 days of HPC series from School of computing (as a PhD student @ CDT for AI for Medical Diagnosis and Care)! Read More ›
Blog post number 9 in our 12 days of HPC series from School of computing (as a PhD student @ CDT for AI for Medical Diagnosis and Care)! Read More ›
blog – 2022-12-08 - 🎄12 Days of HPC 2022
![]() Blog post number 8 in our 12 days of HPC series from Faculty of Environment! Read More ›
Blog post number 8 in our 12 days of HPC series from Faculty of Environment! Read More ›
blog – 2022-12-07 - 🎄12 Days of HPC 2022
![]() Blog post number 7 in our 12 days of HPC series from School of Geography! Read More ›
Blog post number 7 in our 12 days of HPC series from School of Geography! Read More ›
blog – 2022-12-06 - 🎄12 Days of HPC 2022
![]() Blog post number 6 in our 12 days of HPC series from Food Science and Nutrition! Read More ›
Blog post number 6 in our 12 days of HPC series from Food Science and Nutrition! Read More ›
blog – 2022-12-05 - 🎄12 Days of HPC 2022
![]() Blog post number 5 in our 12 days of HPC series from Physics (Astrophysics)! Read More ›
Blog post number 5 in our 12 days of HPC series from Physics (Astrophysics)! Read More ›
blog – 2022-12-04 - 🎄12 Days of HPC 2022
![]() Blog post number 4 in our 12 days of HPC series from Faculty of Biological Sciences ! Read More ›
Blog post number 4 in our 12 days of HPC series from Faculty of Biological Sciences ! Read More ›
blog – 2022-12-03 - 🎄12 Days of HPC 2022
![]() Blog post number 3 in our 12 days of HPC series from Economics! Read More ›
Blog post number 3 in our 12 days of HPC series from Economics! Read More ›
blog – 2022-12-02 - 🎄12 Days of HPC 2022
![]() Blog post number 2 in our 12 days of HPC series from Physics, Maths, Biology, Computer Science, Medicine! Read More ›
Blog post number 2 in our 12 days of HPC series from Physics, Maths, Biology, Computer Science, Medicine! Read More ›
blog – 2022-12-01 - 🎄12 Days of HPC 2022
![]() Blog post number 1 in our 12 days of HPC series from Leeds Institute of Medical Research at St James's! Read More ›
Blog post number 1 in our 12 days of HPC series from Leeds Institute of Medical Research at St James's! Read More ›
blog – 2022-11-09 - 🎄12 Days of HPC is back!
![]() Submit your HPC story and we'll showcase our amazing users during our festive blog series in December Read More ›
Submit your HPC story and we'll showcase our amazing users during our festive blog series in December Read More ›
blog – 2022-10-13 - RSE
![]() Celebrating RSEs and their contribution to science at Leeds Read More ›
Celebrating RSEs and their contribution to science at Leeds Read More ›
blog – 2022-09-27 - Training
Places are now available for upcoming Research Computing training courses, sign up now! Read More ›
blog – 2022-06-07 - Training
Places are now available for upcoming Research Computing training courses, sign up now! Read More ›
blog – 2022-02-21 - Training
Places are now available for upcoming Research Computing training courses, sign up now! Read More ›
blog – 2021-12-19 - 🎄12 Days of HPC 2021
 Blog post number 19 in our 12 days of HPC series from Faculty of Medicine and Health! Read More ›
Blog post number 19 in our 12 days of HPC series from Faculty of Medicine and Health! Read More ›
blog – 2021-12-18 - 🎄12 Days of HPC 2021
Blog post number 18 in our 12 days of HPC series from Centre for Doctoral Training in Artificial Intelligence for Medical Diagnosis and Care! Read More ›
blog – 2021-12-17 - 🎄12 Days of HPC 2021
Blog post number 17 in our 12 days of HPC series from School of Earth & Environment - Institute for Climate & Atmospheric Science! Read More ›
blog – 2021-12-16 - 🎄12 Days of HPC 2021
Blog post number 16 in our 12 days of HPC series from Leeds Institute of Medical Research! Read More ›
blog – 2021-12-15 - 🎄12 Days of HPC 2021
Blog post number 15 in our 12 days of HPC series from Leeds Institute for Data Analytics! Read More ›
blog – 2021-12-14 - 🎄12 Days of HPC 2021
Blog post number 14 in our 12 days of HPC series from Faculty of Biological Sciences! Read More ›
blog – 2021-12-13 - 🎄12 Days of HPC 2021
Blog post number 13 in our 12 days of HPC series from School of Computing and Faculty of Biological Sciences! Read More ›
blog – 2021-12-12 - 🎄12 Days of HPC 2021
Blog post number 12 in our 12 days of HPC series from LeedsOmics (FBS & FMH)! Read More ›
blog – 2021-12-11 - 🎄12 Days of HPC 2021
Blog post number 11 in our 12 days of HPC series from School of Chemistry! Read More ›
blog – 2021-12-10 - 🎄12 Days of HPC 2021
Blog post number 10 in our 12 days of HPC series from Computing! Read More ›
blog – 2021-12-09 - 🎄12 Days of HPC 2021
Blog post number 9 in our 12 days of HPC series from Marketing! Read More ›
blog – 2021-12-08 - 🎄12 Days of HPC 2021
Blog post number 8 in our 12 days of HPC series from School of Food Science & Nutrition! Read More ›
blog – 2021-12-07 - 🎄12 Days of HPC 2021
Blog post number 7 in our 12 days of HPC series from Faculty of Science Sciences and School of Languages Cultures & Societies! Read More ›
blog – 2021-12-06 - 🎄12 Days of HPC 2021
Blog post number 6 in our 12 days of HPC series from School of Geography on identifying birds using cutting hedge technology! Read More ›
blog – 2021-12-05 - 🎄12 Days of HPC 2021
Blog post number 5 in our 12 days of HPC series from School of languages, culture and societies, Centre for translation studies! Read More ›
blog – 2021-12-04 - 🎄12 Days of HPC 2021
Blog post number 4 in our 12 days of HPC series from School of Languages! Read More ›
blog – 2021-12-03 - 🎄12 Days of HPC 2021
Blog post number 3 in our 12 days of HPC series from Astbury Centre/Biological Sciences/Physics/Maths/Computer Science! Read More ›
blog – 2021-12-02 - 🎄12 Days of HPC 2021
Blog post number 2 in our 12 days of HPC series from Computational Imaging & Simulation Technologies in Biomedicine (CISTIB) Group within the School of Computing! Read More ›
blog – 2021-12-01 - 🎄12 Days of HPC 2021
Blog post number 1 in our 12 days of HPC series from Leeds Institute of Clinical Trials Research! Read More ›
blog – 2021-11-10 - 🎄12 Days of HPC
Back for 2021 is our 12 Days of HPC festive blog series! Do you have a good HPC story to share? Submit it now! Read More ›
blog – 2021-10-19 - Training
Places are now available for upcoming Research Computing training courses, sign up now! Read More ›
blog – 2021-03-05 - RSE Showcase
 Showcasing a recent RSE project to help encourage reproducible research practices in a COVID modelling project Read More ›
Showcasing a recent RSE project to help encourage reproducible research practices in a COVID modelling project Read More ›
blog – 2020-12-18 - Events
![]() Come along to our Spring 2021 TechTalk series with a range of talks on Tools and Platforms Read More ›
Come along to our Spring 2021 TechTalk series with a range of talks on Tools and Platforms Read More ›
blog – 2020-12-18 - 🎄12 Days of HPC
 One of our two final posts in our 12 days of HPC series looking at using the HPC to study language using AI! Read More ›
One of our two final posts in our 12 days of HPC series looking at using the HPC to study language using AI! Read More ›
blog – 2020-12-18 - 🎄12 Days of HPC
One of our two final posts in our 12 days of HPC series looking at using the HPC to study emojis and emotions! Read More ›
blog – 2020-12-17 - 🎄12 Days of HPC
Blog post number 13 in our 12 days of HPC series looking at using the HPC to study gene expression differences during brain cancer! Read More ›
blog – 2020-12-16 - 🎄12 Days of HPC
Blog post number 12 in our 12 days of HPC series looking at using the HPC to study bacterial biofilms! Read More ›
blog – 2020-12-15 - 🎄12 Days of HPC
Blog post number 11 in our 12 days of HPC series looking at using the HPC to study jet streams with climate models! Read More ›
blog – 2020-12-14 - 🎄12 Days of HPC
Blog post number 10 in our 12 days of HPC series looking at using machine learning to improve the product design process! Read More ›
blog – 2020-12-11 - 🎄12 Days of HPC
Blog post number 9 in our 12 days of HPC series looking at using Deep learning to help forecast rain! Read More ›
blog – 2020-12-10 - 🎄12 Days of HPC
Blog post number 8 in our 12 days of HPC series showing how HPC is used to study some extreme exoplanets! Read More ›
blog – 2020-12-09 - 🎄12 Days of HPC
Blog post number 7 in our 12 days of HPC series showing how HPC is used to study clouds and the climate! Read More ›
blog – 2020-12-08 - 🎄12 Days of HPC
Blog post number 6 in our 12 days of HPC series showing how the HPC us used to study exoplanets! Read More ›
blog – 2020-12-07 - 🎄12 Days of HPC
Blog post number 5 in our 12 days of HPC series showing how HPC is used to simulate proteins interacting with biological membranes! Read More ›
blog – 2020-12-04 - 🎄12 Days of HPC
Blog post number 4 in our 12 days of HPC series looking at the physics of biomaterials! Read More ›
blog – 2020-12-03 - 🎄12 Days of HPC
Blog post number 3 in our 12 days of HPC series is all about surfactant solutions! Read More ›
blog – 2020-12-02 - 🎄12 Days of HPC
Blog post number 2 in our 12 days of HPC series and we're off to learn about YIGs! Read More ›
blog – 2020-12-01 - 🎄12 Days of HPC
The first blog post in our 12 days of HPC blog series looking at molecular motors! Read More ›
blog – 2020-04-07 - Using HPC
 Helping COVID-19 research using HPC and configuring old systems to run new code. Read More ›
Helping COVID-19 research using HPC and configuring old systems to run new code. Read More ›
blog – 2018-09-07 - Using HPC
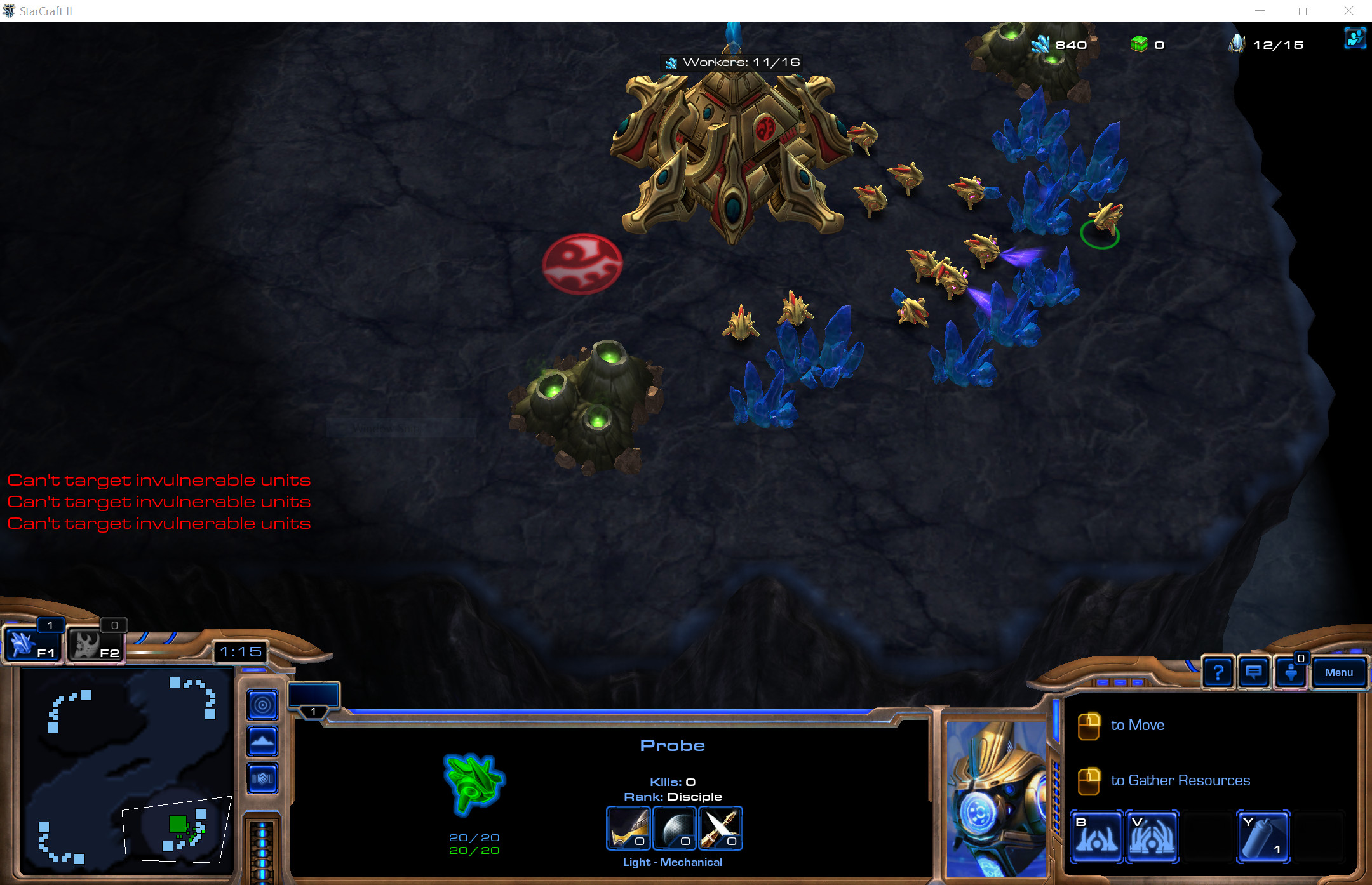 Replicating DeepMinds work applying deep learning to the computer game StarCraft II using GPUs on the HPC at Leeds. Read More ›
Replicating DeepMinds work applying deep learning to the computer game StarCraft II using GPUs on the HPC at Leeds. Read More ›