
Research Computing History
HPC in Leeds has operated for over 15 years providing researchers direct access to high compute capacity for their research. You can read more about the journey of Research Computing, in particular HPC below.
In 2005, we had about 50 conncurrent users consuming 15 core years a month – which has now grown to around 700 active users consuming 1,000 core years a month. In that time we have helped well over 2000 researchers from every faculty of our University and beyond who, between them, have used over 80 thousand core years of computer time. At our peak, we were using around 0.5 MW of electricity for the IT and cooling.
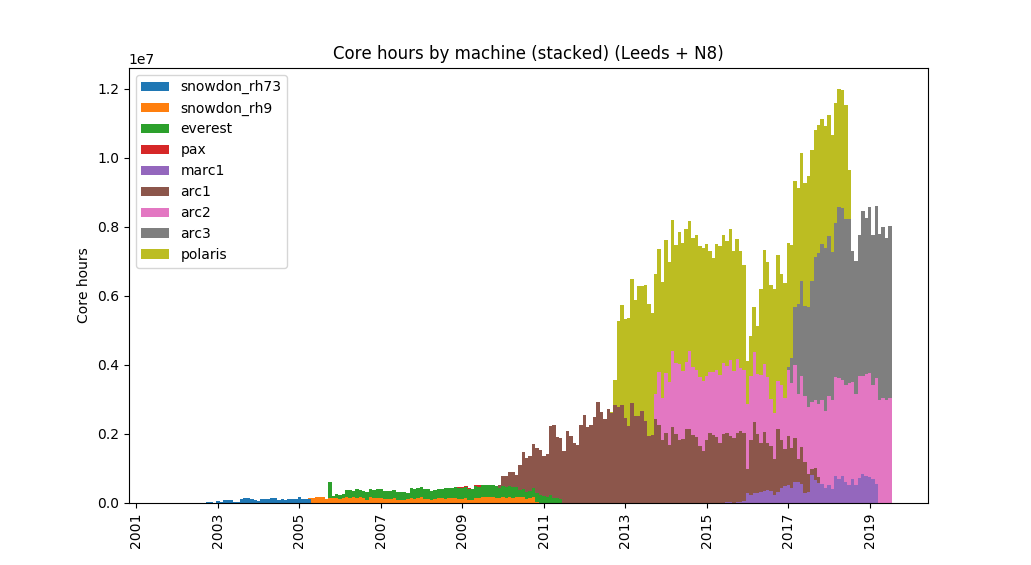
Number of core hours per month, by machine, since the dawn of time
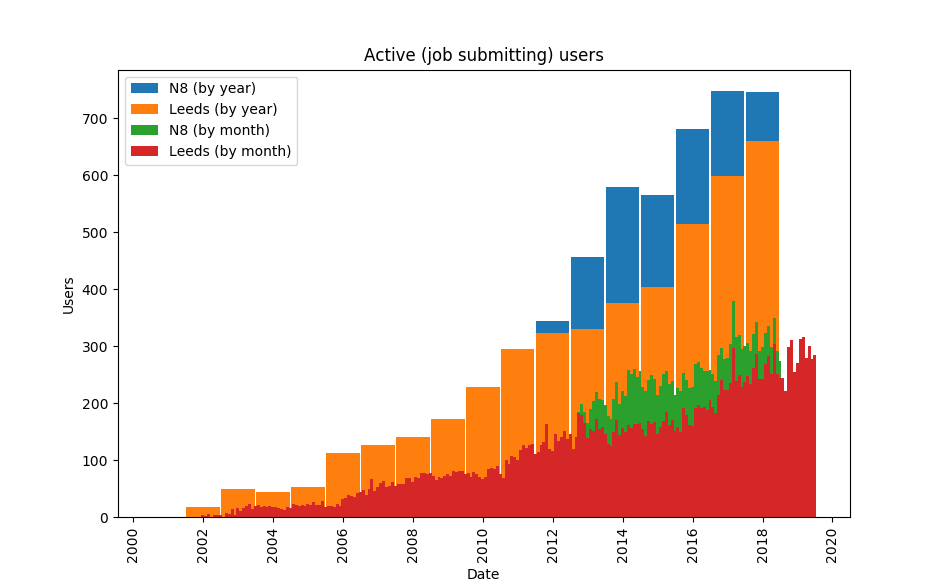
Number of active (i.e. job submitting) users by month and year
Some highlight of researchers’ work that we have supported includes modelling industrial bread ovens; optimising airflow in hospital wards to reduce infection, models of how Leeds’ layout affects the behaviour of burglars, atmospheric science of the prehistoric era, searches for genes that increase the risk of cancer, interstellar gas clouds; the materials science, the machine aided translation of languages.
Procuring, installing and running ~20 tonnes of HPC equipment plus ~20 tonnes of cooling equipment is a big undertaking involving a lot of people as well as the Research Computing team, the IT Datacentre, User Admin, Network and Finance teams; our colleagues in the Estates and Purchasing departments; the IT and specialist hardware vendors; the integrators specialising in racking, wiring and HPC technologies; the electrical and mechanical engineering companies; the hardware break/fix engineers.
In 2009 the University committed to the “ARC” (Advanced Research Computing) series of machines and a water cooling system – funded by all the Faculties, but free at the point of use for every researcher at the institution.
We have been members of several collaborations: the White Rose Grid; the National Grid Service, the first phase of funding for the DiRAC consortium; and the N8 group of research intensive universities in the north of England, for whom we ran its shared regional supercomputer (polaris).
Snowdon and Everestt were part of the White Rose Grid and named after white roses (not after mountains), a nod to the Yorkshire Rose (between us, Sheffield, York and Leeds Universities got quite good at naming machines after roses – iceberg, chablis, akito, saratoga, pax, popcorn, pascali, etc. – although we did start to run out towards the end):

Snowdon (2002-2010)

Everest (2005-2011)

ARC1 and DiRAC compute racks (2009-2017)

Polaris (2012-2018) (left) and ARC2 (2013-) (right) infrastructure racks

ARC3 (2017-) compute node