Posts Search
26 Results

Calder Progress Update – July 2026
Calder, the University’s next HPC cluster, has reached a major milestone with core infrastructure now installed and secured, as the project moves into penetration testing and preparation for user acceptance testing.

Open by Design: Tools for Moving Beyond Open Outputs
A curated collection of resources for researchers and professional service teams interested in embedding openness earlier in the design process through participatory, user-centred and evidence-informed approaches.

How Green Is Your Workflow? Practical Steps for Sustainable AI Research
Generative AI is lowering the barrier to powerful computational research, but it brings often-hidden environmental costs. This article explores how choices about models, workflows and infrastructure shape resource use, and outlines practical questions researchers can ask to make their work more sustainable.
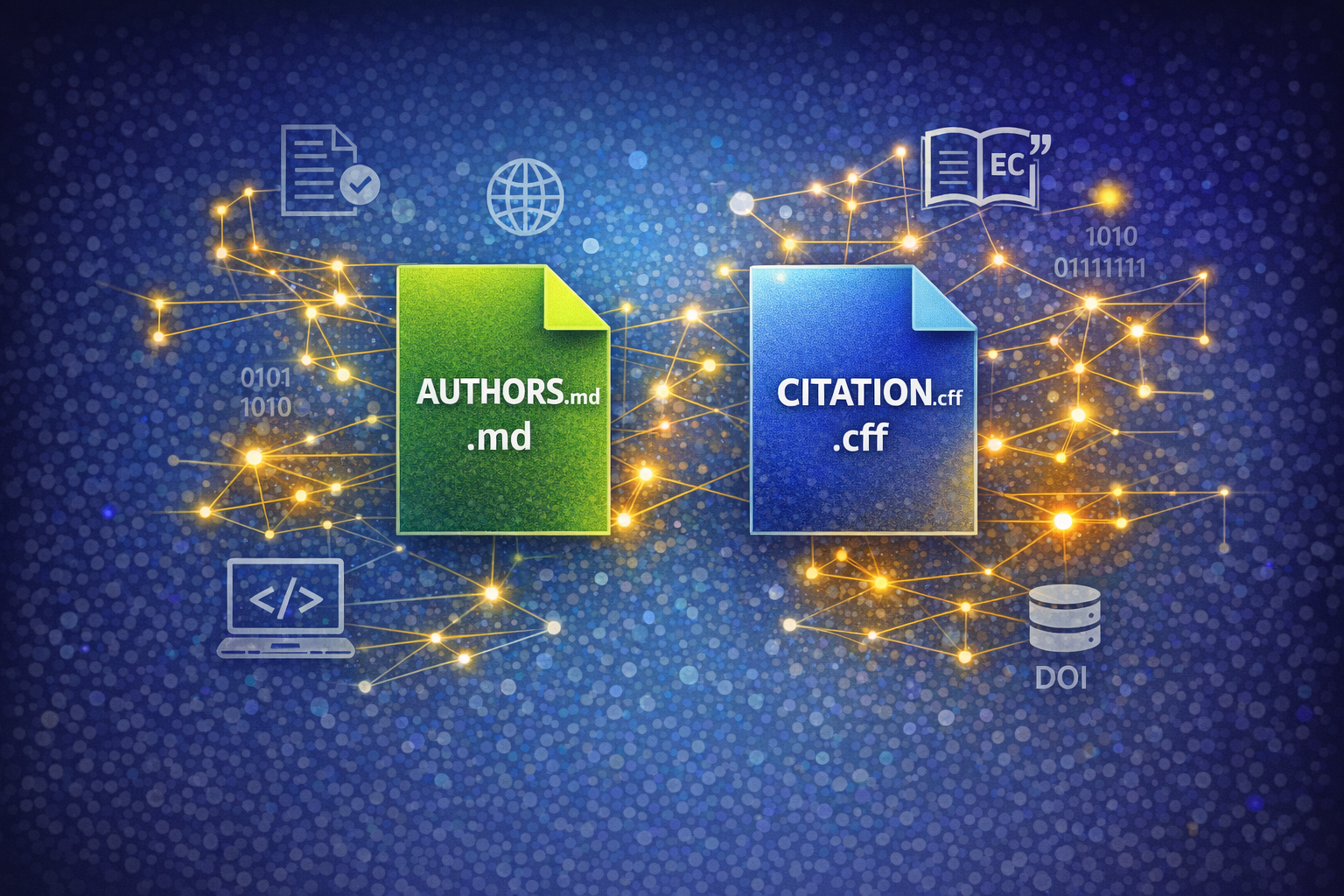
How to Make Your Research Software Citable
Making your research software citable means you get credit for that work and others can build on it with confidence. This practical guide will show you how.

N8CIR Digital Research Internships 2026: Applications Now Open
Applications are now open for the 2026 N8 Digital Research Internships, offering undergraduate students the chance to work on real research projects with our team this summer.

Research Storage Pricing Update – August 2026
From 1 August 2026, pricing for the University’s Research Data Storage service will change due to rising demand for storage.

Calder Progress Update – March 2026
Calder, the University’s next HPC cluster, continues to take shape as a steady stream of hardware arrives.

Call open for RSE summer internship project proposals
Got a research idea gathering dust? Find out how an RSE summer internship could help breathe life into it.

From Overload to Clarity
Key learnings from our recent RSE learning event, From Overload to Clarity - a day spent exploring user-centred service design and systems thinking.
1/3