
RSE Showcase
Helping COVID modelling efforts
Over the past few months Alex Coleman from the Research Computing RSE team has been contributing to the Rapid Assistance in Modelling the Pandemic (RAMP) initiative Urban Analytics project with researchers in Leeds and across the UK.
The RAMP Urban Analytics project led by Professor Mark Birkin from the University of Leeds and the Alan Turing Institute and involved working closely with Professor Nick Malleson, also from the University of Leeds and other researchers from Leeds, Exeter and Cambridge universities and University College London. It aimed to develop a simulation that combined individual interactions, such as going to work, school and shopping, and disease transmission dynamics.
The initial model work focused on the population of Devon and provides a high resolution simulation that connects individual behaviour with disease spread. The model offers the opportunity to test different scenarios and generate hypotheses about different policy interventions or behaviours. The project code was primarily developed in R/Python and is available via GitHub, the project also teamed up with Improbable who helped develop a GUI-assisted OpenCL implementation of the model that allows for GPU-accelerating simulations.
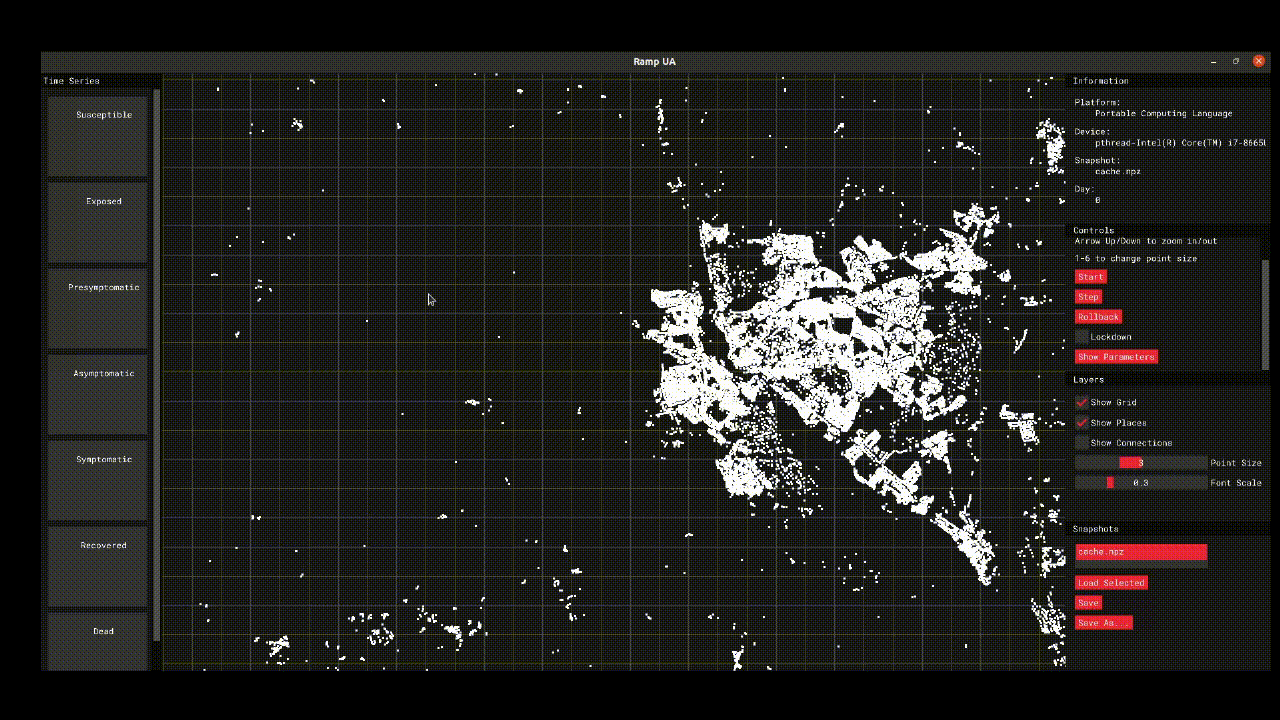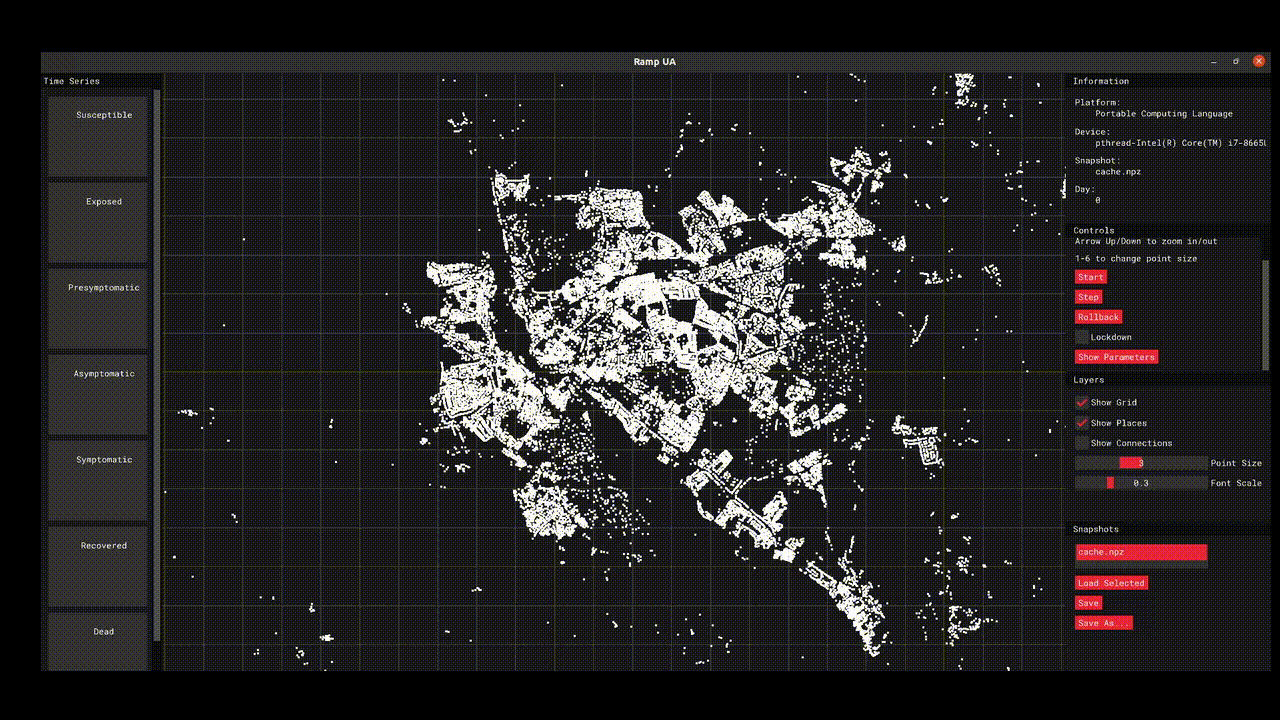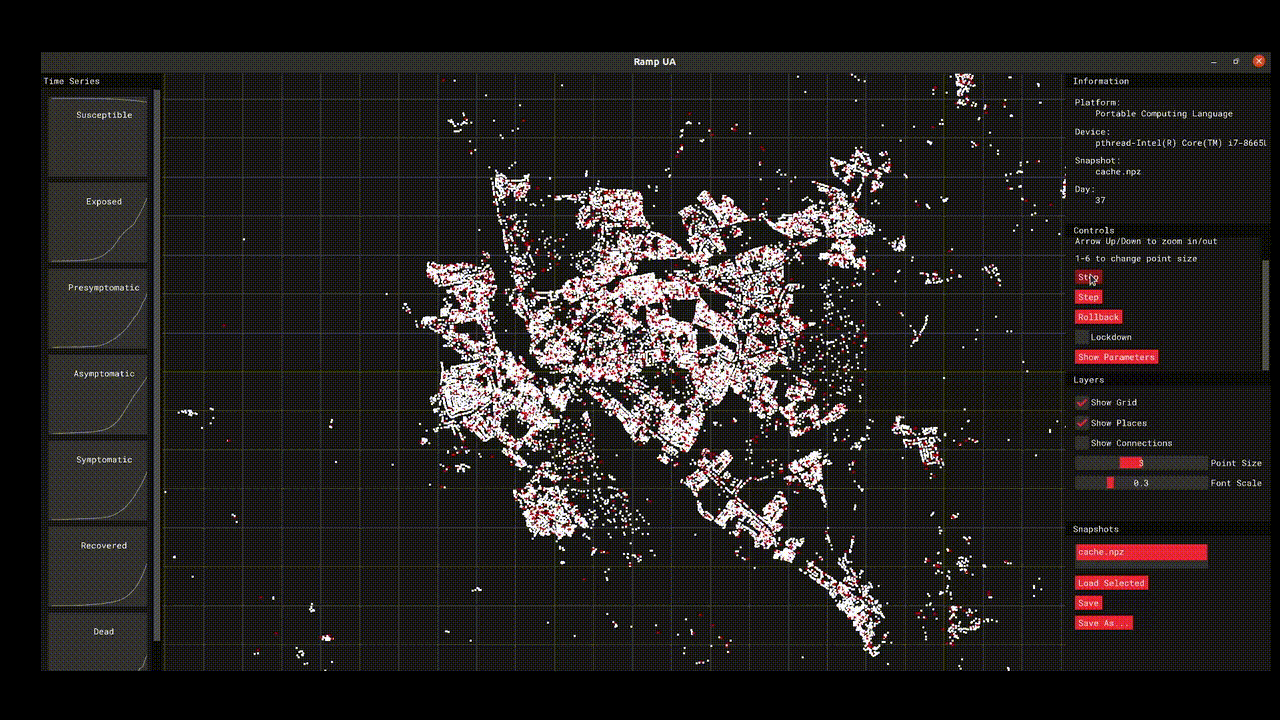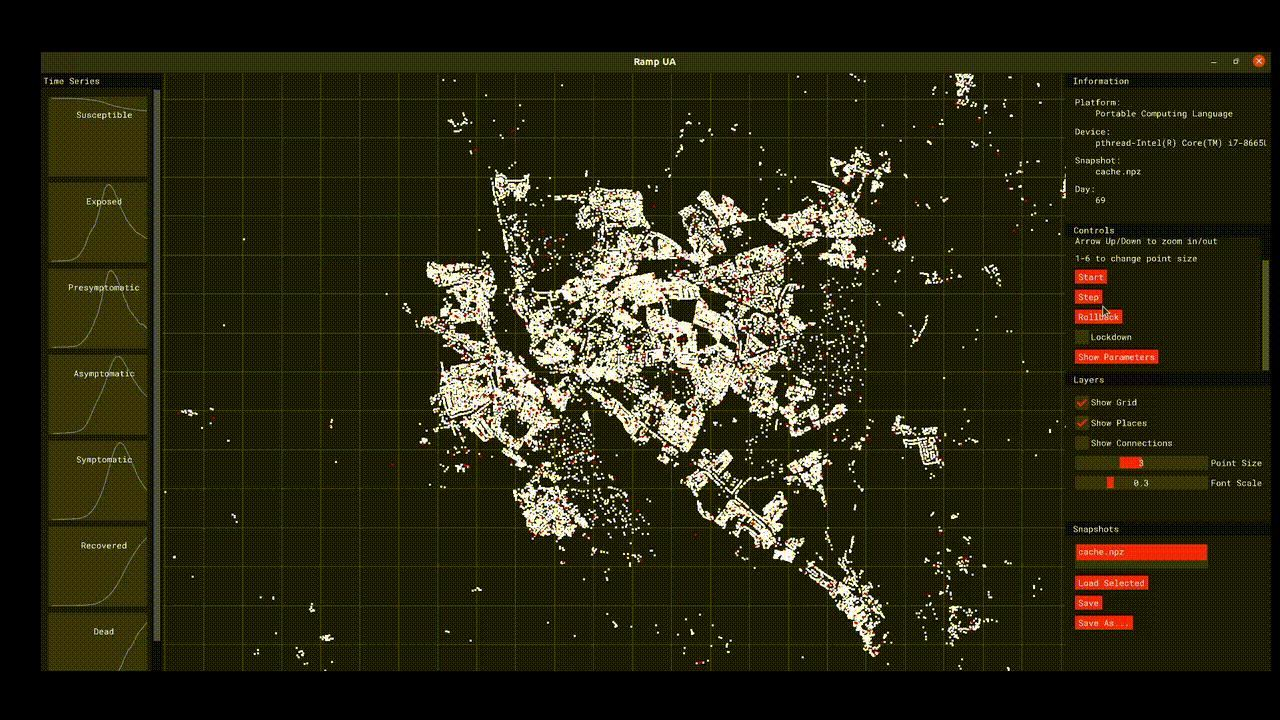
What has an RSE contributed to this project?
As an RSE embedded in this project I’ve been involved in encouraging software development best practise particularly around reproducible research. This focused on small, simple steps that could be incorporated into the researchers workflow to help them just get on with writing the implementation of the model:
1. Using GitHub actions to include a workflow for running the code test suite before merging pull requests
Testing the research code we write is a crucial step in developing research software. At the very least its a sanity check that the function we just wrote does what we think it does. Getting into the habit of writing tests as you write your research code is an important skill that helps you stretch your thinking about what your code is supposed to do and how it should react in different circumstances. Ideas around test-driven development are an extension of this approach and one we strongly encourage researchers to learn more about. For a large project like this we sought to add quality control steps to ensure the model remained functional as changes were made to the codebase. Using GitHub actions a workflow was developed to automatically run the test suite whenever code changes were proposed through pull requests. This is a key quality control step to help reduce the introduction of changes that broke the codebase to help researchers feel more confident as they continued to develop the code.
2. Making the most out of GitHub repository tools
GitHub repositories come with a range of tools to help developers. We’ve touched on some already including GitHub actions but to help us coordinate work on this project we initially utilized GitHub Teams. This is a message board for members of a team within a GitHub organisation, it provided a space to discuss development ideas and share experimental results. This provided a useful additional channel to discuss things asynchronously outside of the weekly stand-up. Project discussions have since moved to Slack, another workspace management tool that includes some useful automation features. One big takeaway from a project like this is ensuring your team has a channel to discuss work outside of email (which can be exclusory and easily forgotten) and the weekly stand-up calls.
We also took advantage of GitHub issues for keeping track of bugs that we identified and enhancement options for the code. This helps create a history of discussions and work on a specific issue which is viewable by the team and others. Centralising the management of these debates into one specific place helps improve transparency around code development and avoid duplication of effort.
3. Using Sphinx and GitHub pages to create an automated documentation webpage
Documenting your code is another key reproducible research habit its worth fostering. With this project the aim was to include documentation to allow anyone to take this code and run it on their own system and replicate results generated through experimentation. Sphinx is a documentation generator commonly used alongside readthedocs. As researchers wrote the model they included docstrings within the code which we wanted to build into a documentation page for the project. The autodocs Sphinx extension makes this easy, allowing for docstrings to be extracted from code and rendered into reStructured Text which is used by Sphinx. Next, we wanted to automate the generation of documentation, to achieve this we looked to GitHub actions and GitHub pages. GitHub pages lets us host a simple static website associated with the code repository (just what we needed) and GitHub actions allows us to create automated workflows that run on specific conditions. In our case we adapted the workflow (view our workflow) for building Sphinx documentation and then utilized an existing action that deploys a specific directory to the gh-pages branch (which is where GitHub pages are rendered from). This allows for the documentation to build automatically every time new code is pushed to the master branch and be deployed to GitHub pages helping researchers just write their code and associated docstrings and worry less about writing out more documentation.
4. Holding weekly developer stand ups
Working with a team distributed across the UK and all working on different aspects of the code meant it was crucial to instigate good practices around distributed team working. At the core of this was organising a weekly stand-up Microsoft Teams Call where everyone working on the code base would join for just half an hour, once a week to go through what they’d been up to, what their plans were and to identify anything blocking or potentially blocking their progress. This helped everyone keep pace with the project and make sure others were able to know what was happening and whether there was anything they could contribute. To aid with this we initially used the Teams feature within GitHub organisations which was covered in 2.
5. Repository organisation
Getting the organisation of a project right is crucial to making your work reproducible and more than anything else good for your own sanity as you embark on writing your code. With this project being a mix of Python and R we took a decision early on to create two separate code repositories: one for the Python code and one for the R package. Both of these repositories follow the standard templates for packages in their respective languages although adapted for the specifics of this particular projects. Imposing these structures early was an important step to ensure the code is as accessible as possible and to avoid duplication with developers working asynchronously on the project.
6. Environment specification
A core pillar of ensuring everyone in the team was able to work on the project from their own setup was to ensure a project environment specification. There’s plenty of tools available for managing this but due to its widespread use in the Python community we opted for conda. This allows all researchers to work on the project within a specific environment where all package versions are the same so we can ensure consistent behaviour of the model. It also allows us to provide a file within the repository that includes that specification so that anyone can recreate the environment on their own setup. This wasn’t without hurdles, in particular ensuring we could run the model on all operating systems, due to particular packages we still currently haven’t got the python/R version of the model working on Windows, although the OpenCL model implementation does work on Windows.
Speaking about the impact of having an embedded RSE on this project Professor Nick Malleson said:
Having an RSE involved in our project totally transformed the way that we worked. I’m convinced that the model we built is much more robust and reliable thanks to the use of the tools and techniques that Alex introduced us to. For me, the most important (and simplest) benefit was in learning how to use basic github features, such as issues, pull requests, and branches, as a way to develop code collaboratively and discuss issues as they arise. This was especially important as the code was developed by a team who have been working in different parts of the country so didn’t have the option to talk things over easily face-to-face.
Do you have a research project that would benefit from having an embedded RSE? Get in touch with the Research Computing team for more details via our contact form.